Hello hello !
It is 2a.m. and this is the only time I had to update the blog with the latest events !
I know the blog has been quiet since I opened my startup, and I wish I could be posting a lot more. I have been learning from left, right, center, inside and outside. This is the hardest thing I have done in my life, probably harder than moving to another country where I didn’t know anybody.
A few days ago, I had the opportunity to share a panel of Q&A with Simon Stewart at Novibet offices and also to speak at the Ministry of Testing Athens Meetup (MoT Athens 🇬🇷 ) sharing the stage with Simon, Wim, Noemi and also Diego Molina (Uhul another South American here in Europe 🙌 ).
The panel was really good, we arrived pretty much on brazilian time as we were really bad with directions 😂
Thanks gosh people were still motivated to ask questions when we arrived, and thanks Simon for taking the lead and presenting yourself first !
I know that we had around 200-300 guests like the last time I came to talk at MoT Athens and again people there makes completely the difference! Unique energy that I rarely see in other events where things are too corporative or full of egos (Not sorry for being honest 😂 )
My talk was a little different from the traditional testing presentation.
Instead of focusing on testing software, I explored a question that has been on my mind for quite some time:
What if we tested ourselves the same way we test software?
As testers, we question assumptions, look for edge cases, automate repetitive tasks, measure outcomes, and continuously improve. Yet many of us rarely apply the same rigorous mindset to our own lives, habits, careers, and personal growth.
During the session, I shared what I call the QA Mindset for Self-Growth, built around five principles:
- Question everything.
- Think in edge cases.
- Automate the repeatable.
- Measure what matters.
- Iterate relentlessly.
What started as a framework inspired by software testing has become something I use daily as a founder. Building a company forces you to constantly challenge assumptions, identify risks before they become problems, create systems that scale, and continuously adapt based on feedback.
In many ways, entrepreneurship and quality assurance are surprisingly similar.
Both require you to become comfortable with uncertainty.
Both require you to look what you can control, yourself and take accountability not blaming others.
And both teach you that perfection is not the goal, the journey (continuous improvement) is.
The rest of the meetup was equally inspiring. We heard talks about AI-assisted testing, modern QA practices, security challenges, infrastructure vulnerabilities, and the evolving role of testers in a world increasingly influenced by AI. It was a reminder that our industry continues to move fast, and staying curious is becoming one of the most valuable skills we can develop.
I also loved seeing the community engagement throughout the event. From the interactive quizzes to the networking sessions and conversations between talks, it was clear that MoT Athens has built something special ♥️
In the end the feedback was so positive – but you know me – I like the constructive feedback !
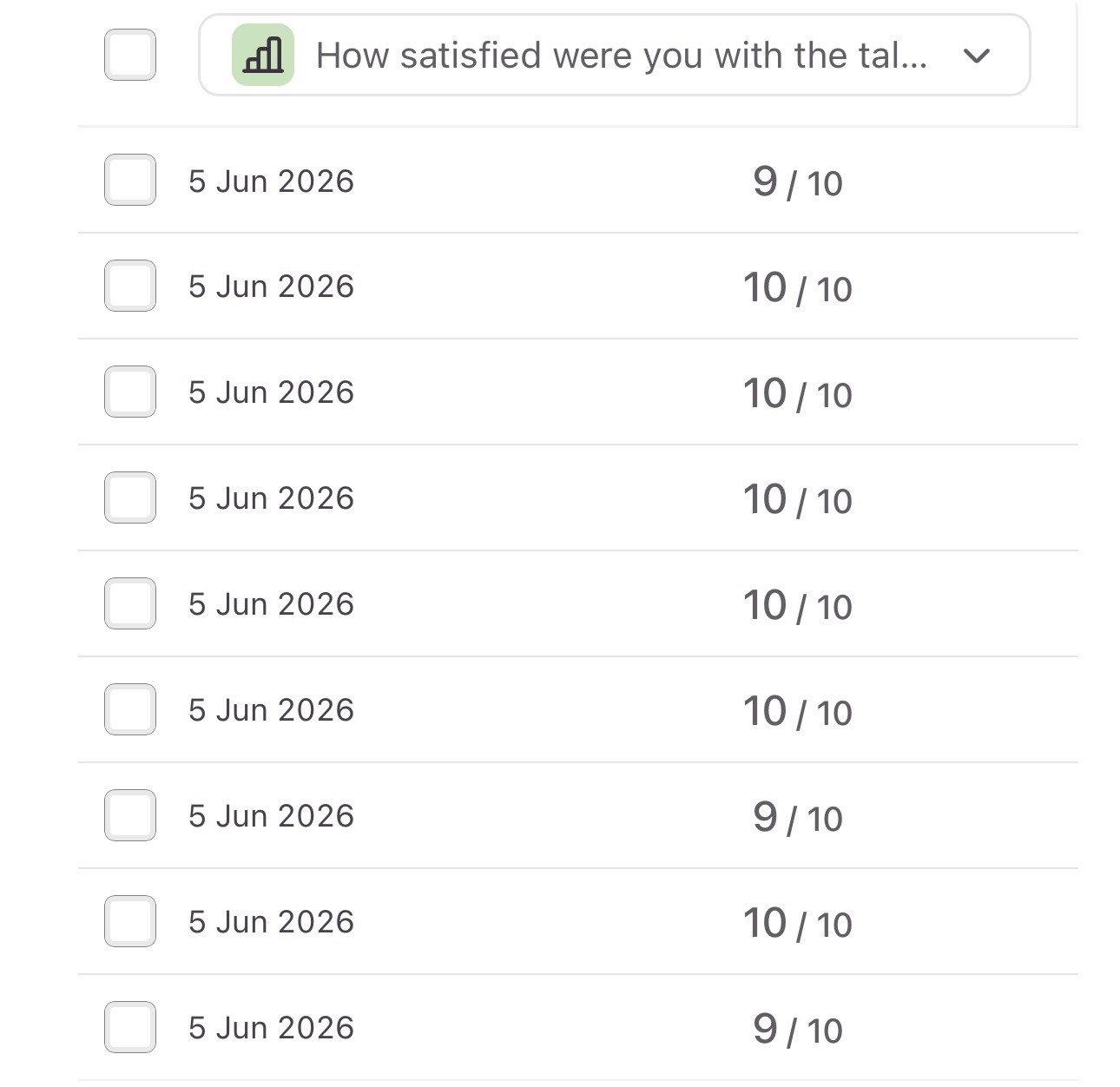
Thanks for Diego for pointing me out the things I can improve for the next and try to reduce my anxiety and my dry mouth and the eternity that looked like when I was finally able to drink water. Of course this wouldn’t be me if I didn’t do something to embarrass myself and I spilled water when I was finally drinking 😂
A huge thank you to the organizers, volunteers, speakers, and everyone who attended. Organizing events like these takes an enormous amount of effort, most of which happens behind the scenes.
Also thanks for Satoshi Nakamoto that was presented there (find him on the quiz picture) – unfortunately he was not the winner, so I couldn’t finally meet him lolz






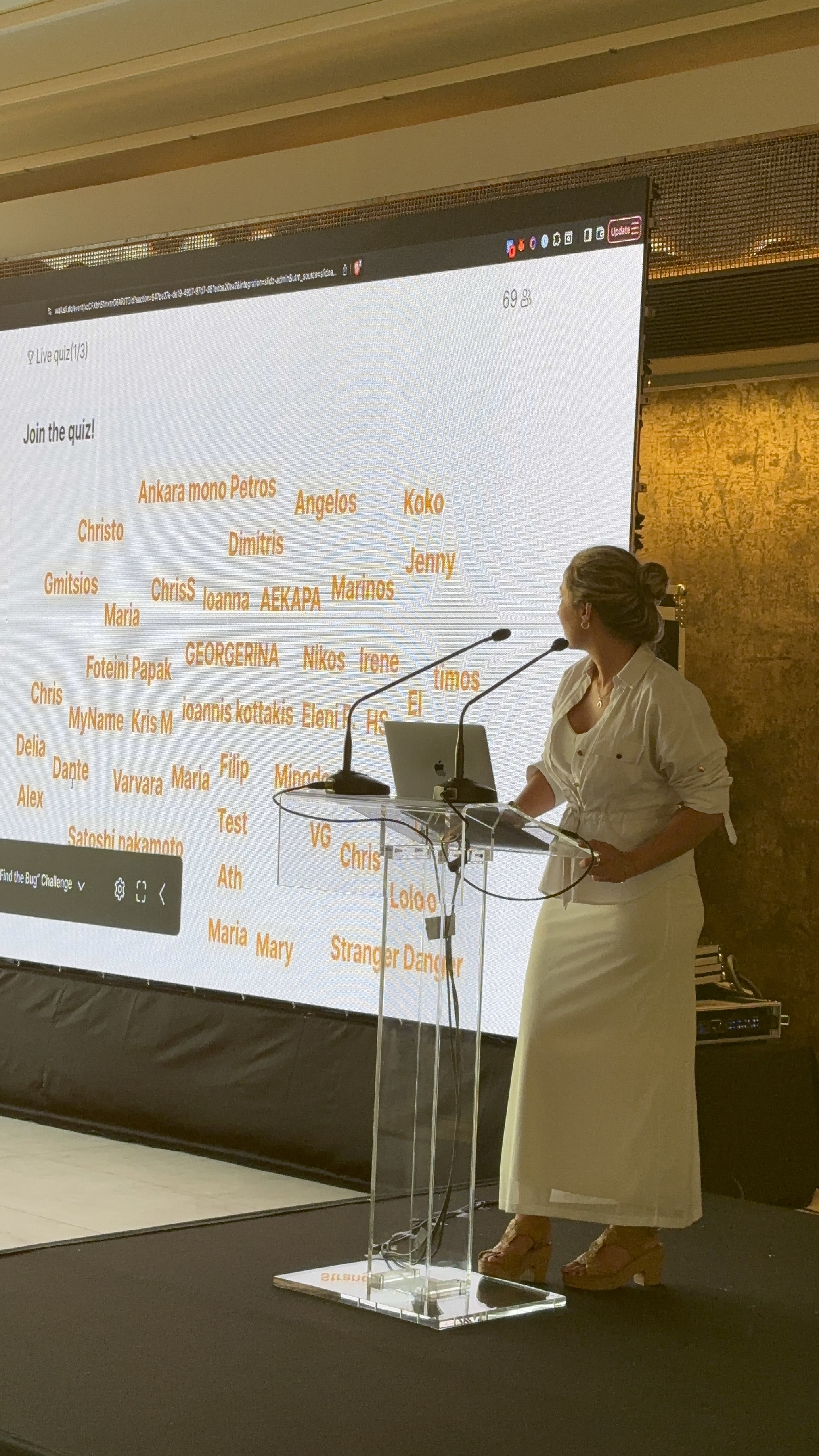




And personally, thank you for welcoming me and giving me the opportunity to share ideas that sit at the intersection of technology, testing and personal development.
Moments like this remind me that growth rarely happens in isolation !
Hopefully, it won’t take me until 2a.m. again to write the next blog post.
Until then, keep going !




































