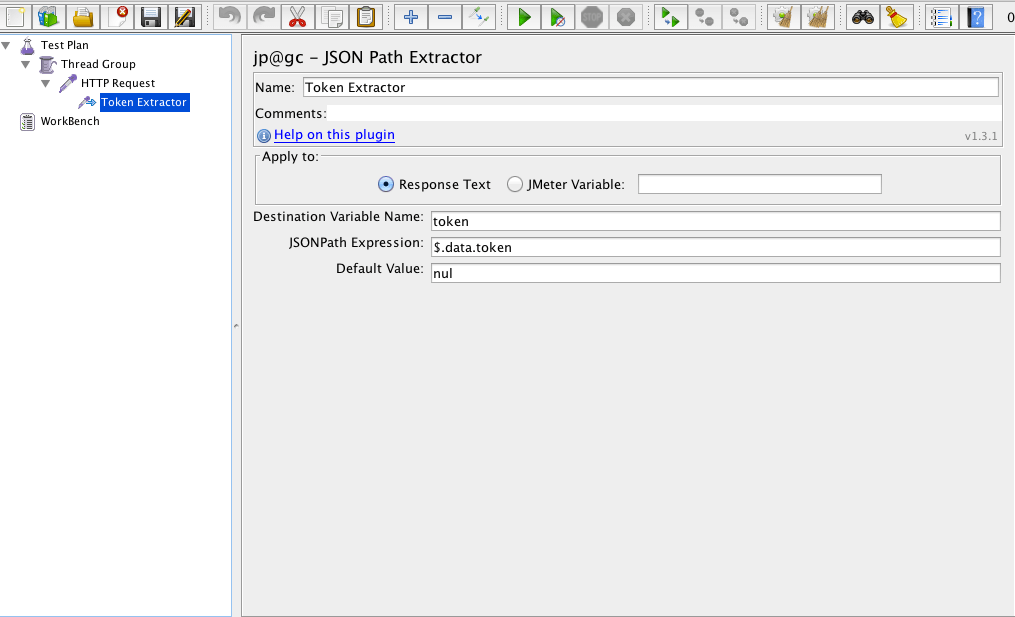
Hey guys, today I am going to post some metrics for the automation projects. So, let’s start with the percentage automatable, which means how many test cases you can automate and how many you need to test manually.
PA (%) = ATC/TC
PA = Percent automatable
ATC = Number of test cases automatable
TC = Total number of test cases
As part of an AST effort, the project is either basing its automation on existing manual test procedures, or starting a new automation effort from scratch, some combination, or even just maintaining an AST effort. Whatever the case, a percent automatable metric or the automation index can be determined.
AP (%) = AA/ATC
AP = Automation progress
AA = Number of test cases automated
ATC = Number of test cases automatable
Automation progress refers to the number of tests that have been automated as a percentage of all automatable test cases. Basically, how well are you doing against the goal of automated testing? The ultimate goal is to automate 100% of the “automatable” test cases. It is useful to track this metric during the various stages of automated testing development.
- Test Progress (Manual or automated)
TP = TC/T
TP = Test progress
TC = Number of test cases executed
T = Total number of test cases

A common metric closely associated with the progress of automation, yet not exclusive to automation, is test progress. Test progress can simply be defined as the number of test cases (manual and automated) executed over time.
- Percent of Automated Test Coverage
PTC (%) = AC/C
PTC = Percent of automated test coverage
AC = Automation coverage
C = Total coverage (i.e., requirements, units/components, or code coverage)
This metric determines what percentage of test coverage the automated testing is actually achieving. Various degrees of test coverage can be achieved, depending on the project and defined goals. Together with manual test coverage, this metric measures the completeness of the test coverage and can measure how much automation is being executed relative to the total number of tests. Percent of automated test coverage does not indicate anything about the effectiveness of the testing taking place; it is a metric that measures its dimension.
DD = D/SS
DD = Defect density
D = Number of known defects
SS = Size of software entity
Defect density is another well-known metric that can be used for determining an area to automate. If a component requires a lot of retesting because the defect density is very high, it might lend itself perfectly to automated testing. Defect density is a measure of the total known defects divided by the size of the software entity being measured. For example, if there is a high defect density in a specific functionality, it is important to conduct a causal analysis. Is this functionality very complex, and therefore is it to be expected that the defect density would be high? Is there a problem with the design or implementation of the functionality? Were the wrong (or not enough) resources assigned to the functionality, because an inaccurate risk had been assigned to it and the complexity was not understood?
DTA = D/TPE
DTA = Defect trend analysis
D = Number of known defects
TPE = Number of test procedures executed over time
Another useful testing metric in general is defect trend analysis.
- Defect Removal Efficiency
DRE (%) = DT/DT+DA
DRE = Defect removal efficiency
DT = Number of defects found during testing
DA = Number of defects found after delivery
DRE is used to determine the effectiveness of defect removal efforts. It is also an indirect measurement of product quality. The higher the percentage, the greater the potential positive impact on the quality of the product. This is because it represents the timely identification and removal of defects at any particular phase.
- Automation Development
Number (or %) of test cases feasible to automate out of all selected test cases – You can even replace test cases by steps or expected results for a more granular analysis.
Number (or %) of test cases automated out of all test cases feasible to automate – As above, you can replace test cases by steps or expected results.
Average effort spent to automate one test case – You can create a trend of this average effort over the duration of the automation exercise.
% Defects discovered in unit testing/ reviews/ integration of all discovered defects in the automated test scripts
- Automation Execution
Number (or %) of automated test scripts executed out of all automated test scripts
Number (or %) of automated test scripts that passed of all executed scripts
Average time to execute an automated test script – Alternately, you can map test cases to automated test scripts and use the Average time to execute one test case.
Average time to analyze automated testing results per script
Defects discovered by automated test execution – As common, you can divide this by severity/ priority/ component and so on.
References:
http://www.methodsandtools.com/archive/archive.php?id=94