Having an alert system is crucial to have confidence in your product. There are 2 main points you need to consider, Monitoring and Alerts:
Monitoring consists of dashboards and reports to display the metrics.
Alerts involve taking some type of action such as notifying someone, writing to a log, and raising an alert on a dashboard.
Having an alert system is crucial to delivering the rightinformation to the rightpeople at the righttime
Important Metrics to Watch
The list is long and you can get lost on all the possible metrics you can watch and raise an alert upon. A good strategy is starting with the riskiest ones, the ones that can stop the system to work, stability, and performance. Here is a list of some of the most-watched metrics:
CPU utilization
Memory utilization
Memory breakup
Load balancer (Number of instances running)
Services and processes running
Processor queue length
Disk usage
Network up
Plugin
Crontab executed
Event logs generated
Application details
Expiring Certificates
Docker/Kubernetes containers
These metrics can be swapped or removed or you can even add others according to your needs. The goal here is to find the best metrics to watch and raise different levels of alerts to the specific group of people at the right time. These metrics can help the team to check the system’s health and also increase the confidence and reliability not only in the recovery steps when something goes sideways but also in the alert system itself.
Different Types of Metrics
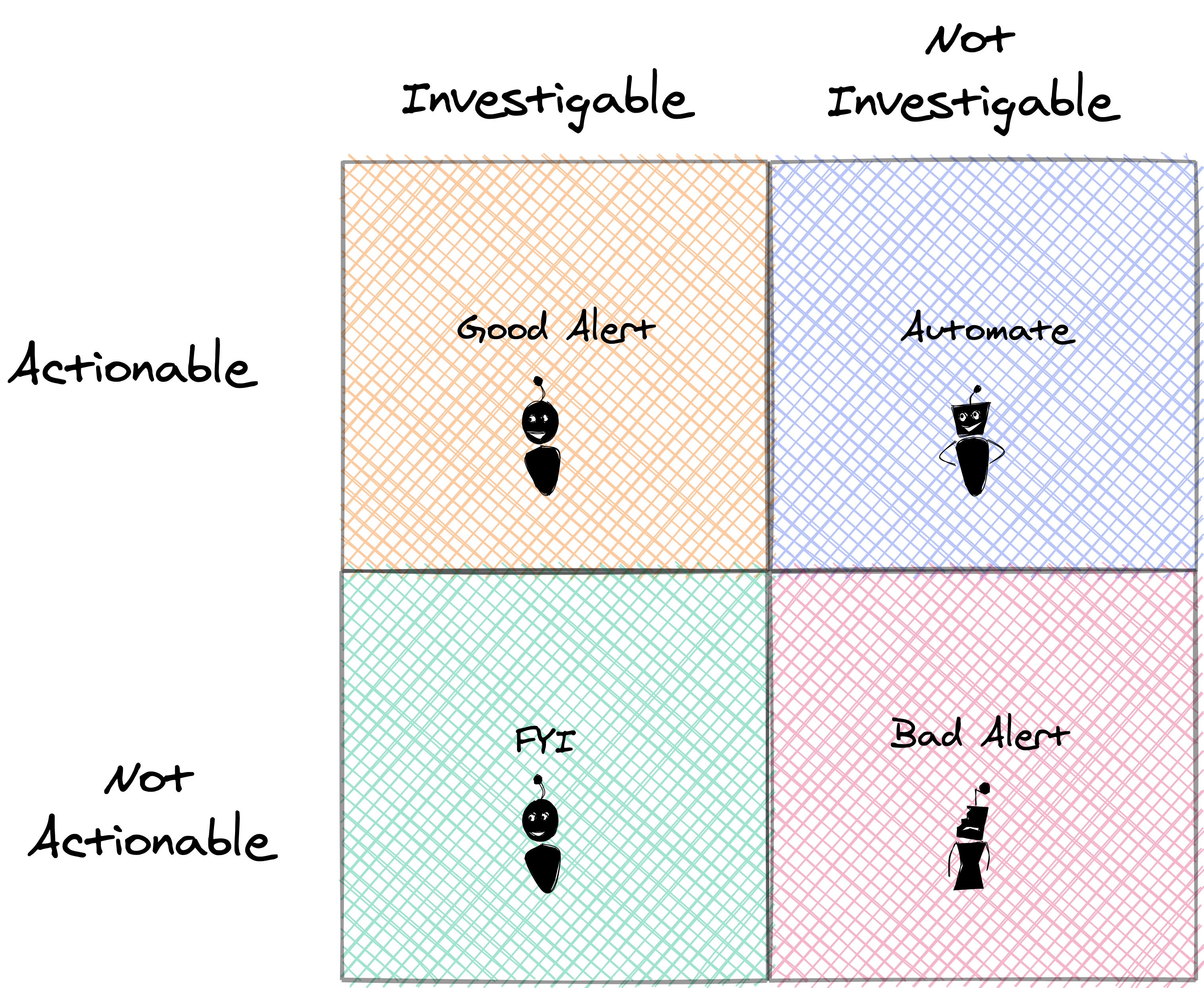
I found this good framework to create a good alert. It needs to have these properties:
Actionable: Indicates a problem for which the recipient is well placed to take immediate action. Investigable: Indicates a problem whose solution is not yet known by the organization.
Do you need to take an action every time? No, you can specify a capacity limit, and then once the metric reaches this limit you can have the first support acting up on it, then when it reaches the second limit then you have a different action like calling the second line support, or calling a script to restart a service, etc.
Sometimes there is no action to take. For example, “CPU utilization” or “Packet loss.” These are some classic FYI alerts. Instead of alerting, these things should appear on a dashboard for use in troubleshooting when a problem is already known to exist.
Do you need to send the alert straight away? Also no, especially when you have mechanisms of self-healing. There’s no need to bother a human to fix the issue; the response should be automated.
Depending on your recovery strategy, you can wait 5, 10, or15 minutes to check if the metric is still showing a problem, and then, if it is you can raise the alert accordingly. In the alert, you can always have a link to the documentation with recovery steps (e.g. a “runbook” indicating steps to perform).
Remember to have an FYI for when the problem is fixed as well, so in case something has failed in the middle of the evening and in the morning is working, you get the latest update about the problem.
Always keep records and logs to investigate what happened and how the system reacted.
Dan Slimmon has a good spreadsheet example of an alert framework:
Monitoring and Alert Tests
Independently the tool you are using for your metrics and alerts: Grafana, Cloudwatch, Sensu, Prometheus, or New Relic. It is important to have a test strategy to cover this critical part of your system.
Some common tests you need to perform are much more Devops related, like scaling down some instances on AWS, simulating a high memory load with scripts, or even creating scripts specific to remove log files from the Docker container.
Points to keep in mind:
Is it worth automating?
Think about if you have a lot of changes and maintenance to the project. How much effort would be to create the automation for these scenarios? How complex these scenarios would be? Does automating them bring any real value?
There are some tools that you can use to perform chaos engineering:
AWS FIS (Fault injection Actions Simulator) to automate some of the scenarios and add to your continuous delivery pipeline. It’s a fully managed service for running fault injection experiments on AWS that makes it easier to improve an application’s performance, observability, and resiliency.
Chaos Mesh utilizes chaos experiments within Kubernetes environments. It’s able to use various types of scenarios related to fault simulations within a distributed system.
Many other tools can be used and you can check the list in this post.
At what stages do you want to test and what scope?
Check if you need to do manual smoke tests for each feature and then have a bigger regression after merging the tickets, or manual test for the feature and at the same time add the automation for this scenario, so at the end of the pipeline, you have the full regression.
Maybe you don’t even need to have automation running for this project and just doing manual feature tests for the tickets and having a report with the full regression scenarios is enough
Whatever is the strategy that you choose, make sure you have the max confidence you can have with the current constraints and a plan to improve in the near future.
Automating these tests is complex and always involves a good knowledge of infrastructure. I personally had and still have to do a lot of research when it comes to it.