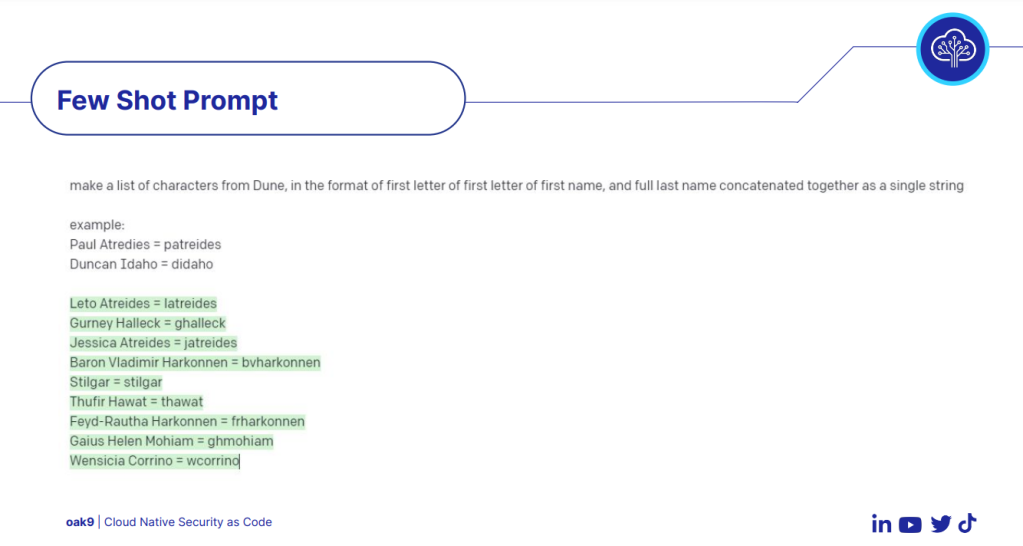
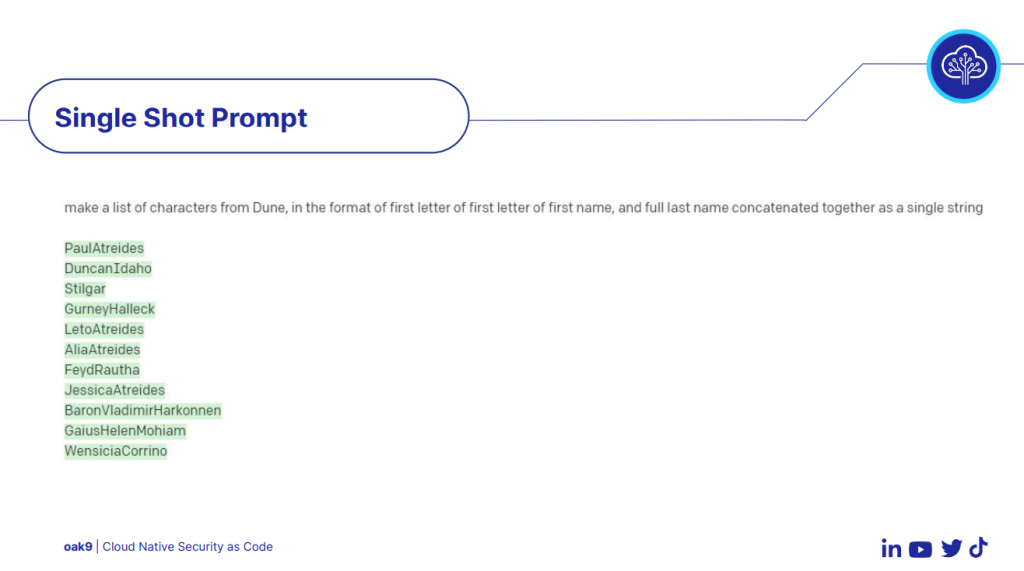
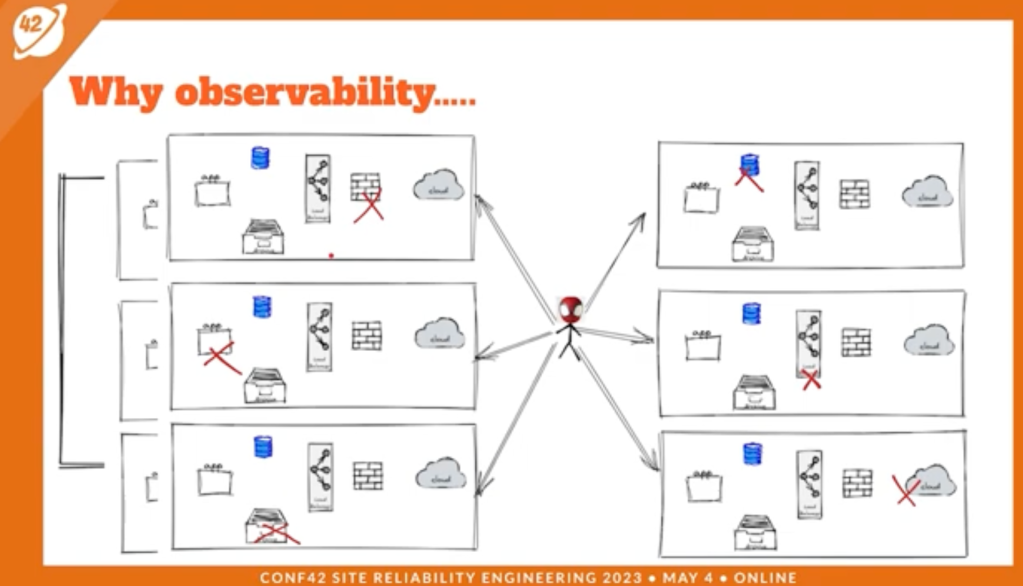
You’ve just refactored your Terraform module to add the auto-scaling magic. You merge. You deploy. You go to bed. The next morning? Production is literally on fire 🔥 because your “tiny” change accidentally nuked the database.
How to stop “Oops” from becoming “OH NO” …
Test-Driven Chaos Prevention 🧪
Terraform tests (available in v1.6+) let you validate config changes before they touch your infrastructure. Think of them as your code’s personal bouncer, checking IDs at the door.
Translation: “If the bucket name isn’t ‘my-glittery-unicorn-bucket,’ error and abort.”
How Terraform Tests Save You 🤗
1️⃣ command = plan: Simulate changes without touching real infra. “What if…?” but for adults. 2️⃣ Assertions: Like a clingy ex, they’ll text you 100x if something’s wrong. Example:
assert {
condition = output.bucket_name == "test-bucket"
error_message = "This is NOT the bucket you’re looking for. 👋"
}
3️⃣ Variables & Overrides: Test edge cases without redeploying. Example: “What if someone sets bucket_prefix to 🔥?”
Some Tips !
Mock Providers (v1.7+): Fake it ’til you make it. Test AWS without paying AWS 👍
Expect Failure: Want to validate that a config should break? Use expect_failures. Example:
run "expect_chaos" {
variables { input = 1 } # Odd number → should fail validation
expect_failures = [var.input]
}
Translation: “If this doesn’t fail, I’ve lost faith in humanity.” (I have already tbh)
Modules in Tests: Reuse setup/teardown logic like a lazy genius. Example: A “test” module that pre-creates a VPC so you can focus on actual work.
The conference as a whole was really interesting but my highlights are:
Replacing Privileged Users With Automated Just-in-Time Access Requests by Travis Rodgers
Managing privileged access to resources can be cumbersome, with developers often needing temporary access beyond their regular duties.
Just-in-time access solutions allow engineers to escalate privileges when necessary, applying the principle of least privilege in a secure manner.
Role-Based Access Control (RBAC): Implementing RBAC further enhances security by defining and assigning roles, reducing the need for admin accounts.
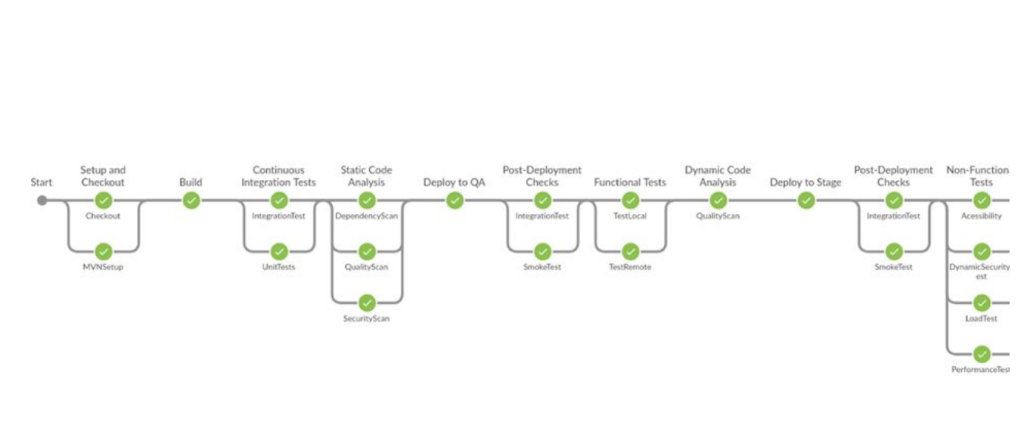
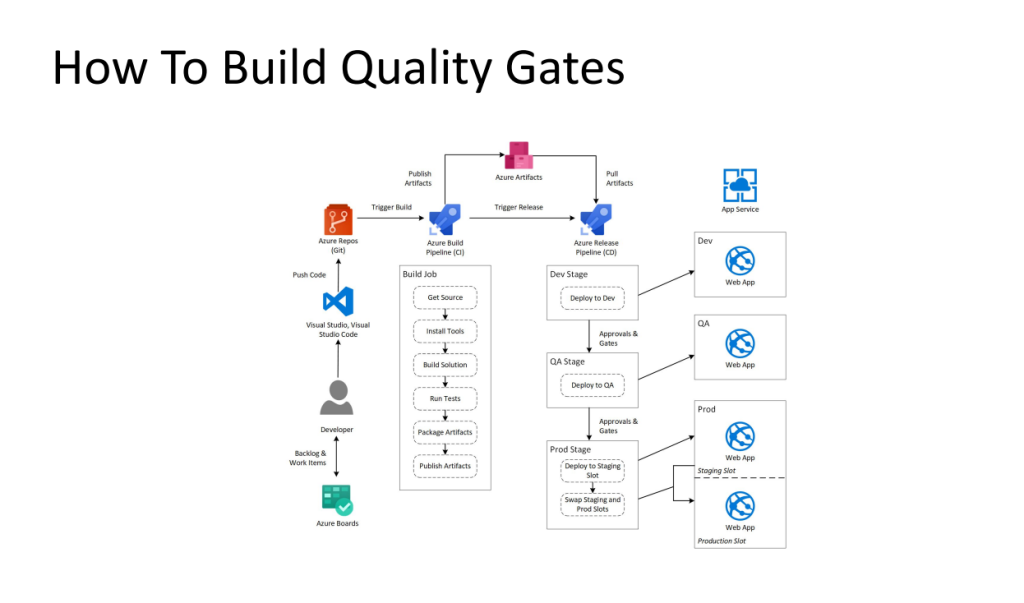
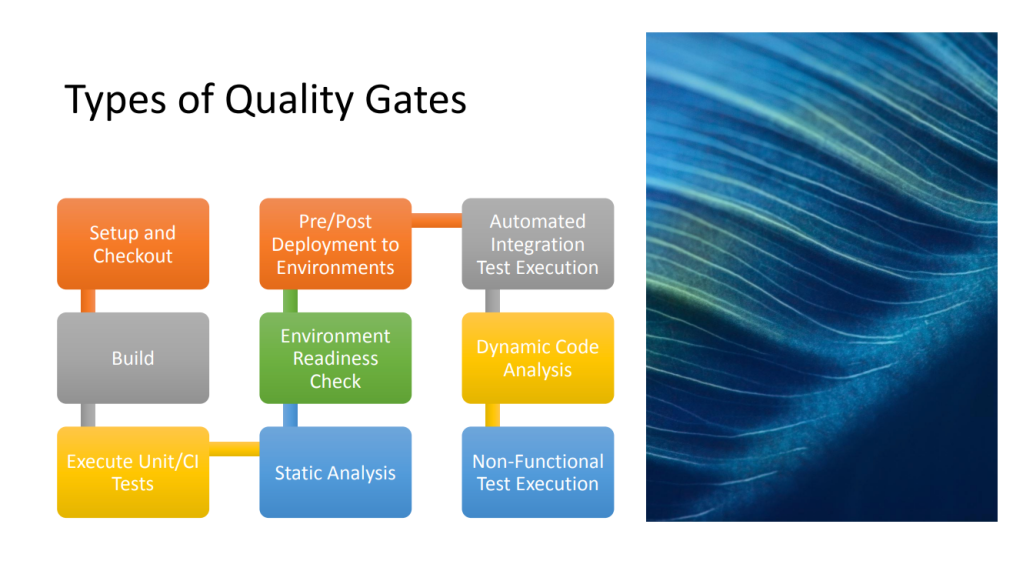
Building Automated Quality Gates into your CI pipelines by Craig Risi (My favourite)
How to incorporate automated quality checks at various stages of the CI pipeline to ensure the delivery of high-quality software.
It highlights the benefits of having automated quality gates in place, including early bug detection and prevention.
Practical guidance on implementing quality gates using tools and techniques such as static code analysis, code coverage analysis, and automated testing.
GPT: Revolutionizing Monitoring and Logging Systems by Clay Langston
Use GPT (Generative Pre-trained Transformer) to enhance logging and monitoring performance.
Maximize log value and improve system performance.
Automate the process by integrating with ELK (Elasticsearch, Logstash, and Kibana).
Construct effective prompts to extract valuable insights from logs.
Observability: one of the strongest muscles for SRE by Jhonnatan Gil Chaves
Focus on the big picture when implementing SRE practices.
Recognize the importance of the team and tools in SRE implementations.
Don’t overlook the broader view of your IT components.
CICD – The SRE-DevOps Overlay by Safeer CM and Garima Bajpai
Site reliability engineering (SRE) and DevOps practices have overlapping boundaries in many organizations.
Continuous integration and continuous delivery (CI/CD) are essential aspects of this overlap.
CI/CD serves as a prerequisite for many core SRE practices.
How to achieve the scalability, high availability, and elastic ability of your database infrastructure on Kubernetes by Trista Pan
How to make the clusters scalable, elastic, and highly available.
Traffic governance between applications and databases plays a crucial role in achieving these goals.
Effective way to manage and distribute traffic.
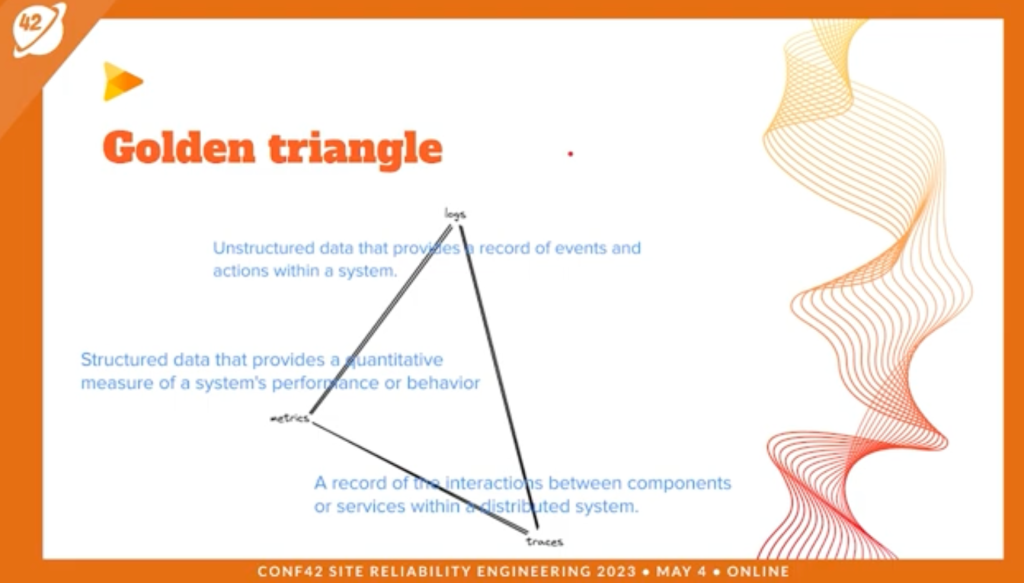
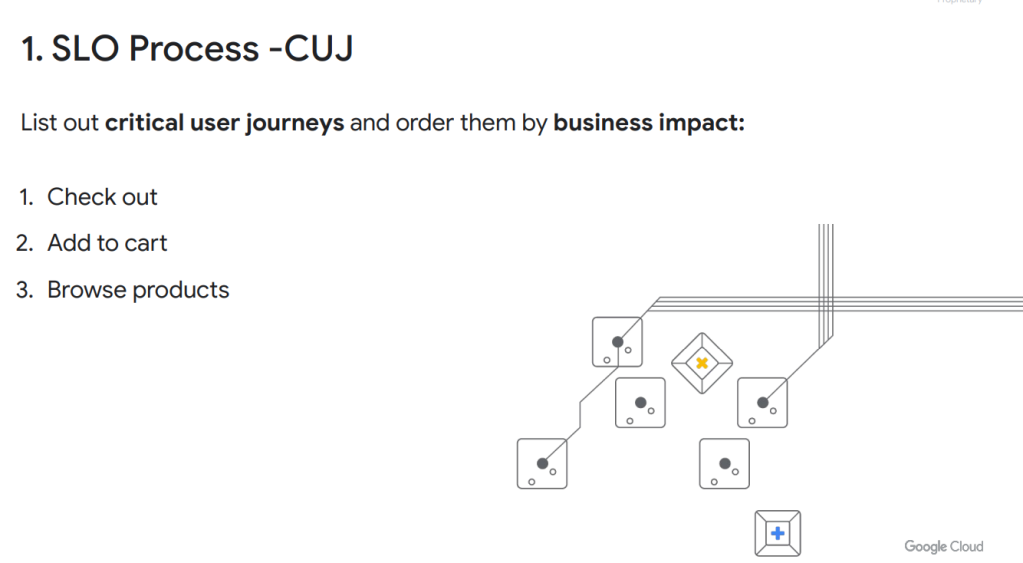
Measuring Reliability in Production Ramon Medrano Llamas
Identifying Critical User Journeys (CUJs) and recommendations for selecting appropriate metrics as SLI and SLO targets.
Practical insights and actionable steps for implementing SLIs and SLOs in your own applications.
If you missed out on Conf42 SRE 2023, fear not! The link with the abstract of the talks, the speakers and other details is here and you can also watch below the talks on youtube 🙌
Last week I joined the Google Cloud Summit 2023 and watched some sessions. The main goal of the conference was, of course, to do a bit of marketing on Google AI and Google Cloud, but was also interesting to see ideas on how you can use AI in different areas.
The event has ended, but you can still watch the sessions on demand, you might need to register your email tho.
Starting
For an overview on Google AI and to see what Google is offering then I suggest starting with this video:
Sessions and Demos
My favourite demos and sessions from the conference:
You can also check this interesting Balancing your Database page where you can select the best relational database between Cloud SQL and Cloud Spanner according to the different traffic patterns.
Learning paths
And to conclude you can also see some of the learning paths for the careers you can achieve, you can enroll for free in any of the courses they provide:
Having an alert system is crucial to have confidence in your product. There are 2 main points you need to consider, Monitoring and Alerts:
Monitoring consists of dashboards and reports to display the metrics.
Alerts involve taking some type of action such as notifying someone, writing to a log, and raising an alert on a dashboard.
Having an alert system is crucial to delivering the rightinformation to the rightpeople at the righttime
Important Metrics to Watch
The list is long and you can get lost on all the possible metrics you can watch and raise an alert upon. A good strategy is starting with the riskiest ones, the ones that can stop the system to work, stability, and performance. Here is a list of some of the most-watched metrics:
CPU utilization
Memory utilization
Memory breakup
Load balancer (Number of instances running)
Services and processes running
Processor queue length
Disk usage
Network up
Plugin
Crontab executed
Event logs generated
Application details
Expiring Certificates
Docker/Kubernetes containers
These metrics can be swapped or removed or you can even add others according to your needs. The goal here is to find the best metrics to watch and raise different levels of alerts to the specific group of people at the right time. These metrics can help the team to check the system’s health and also increase the confidence and reliability not only in the recovery steps when something goes sideways but also in the alert system itself.
Different Types of Metrics
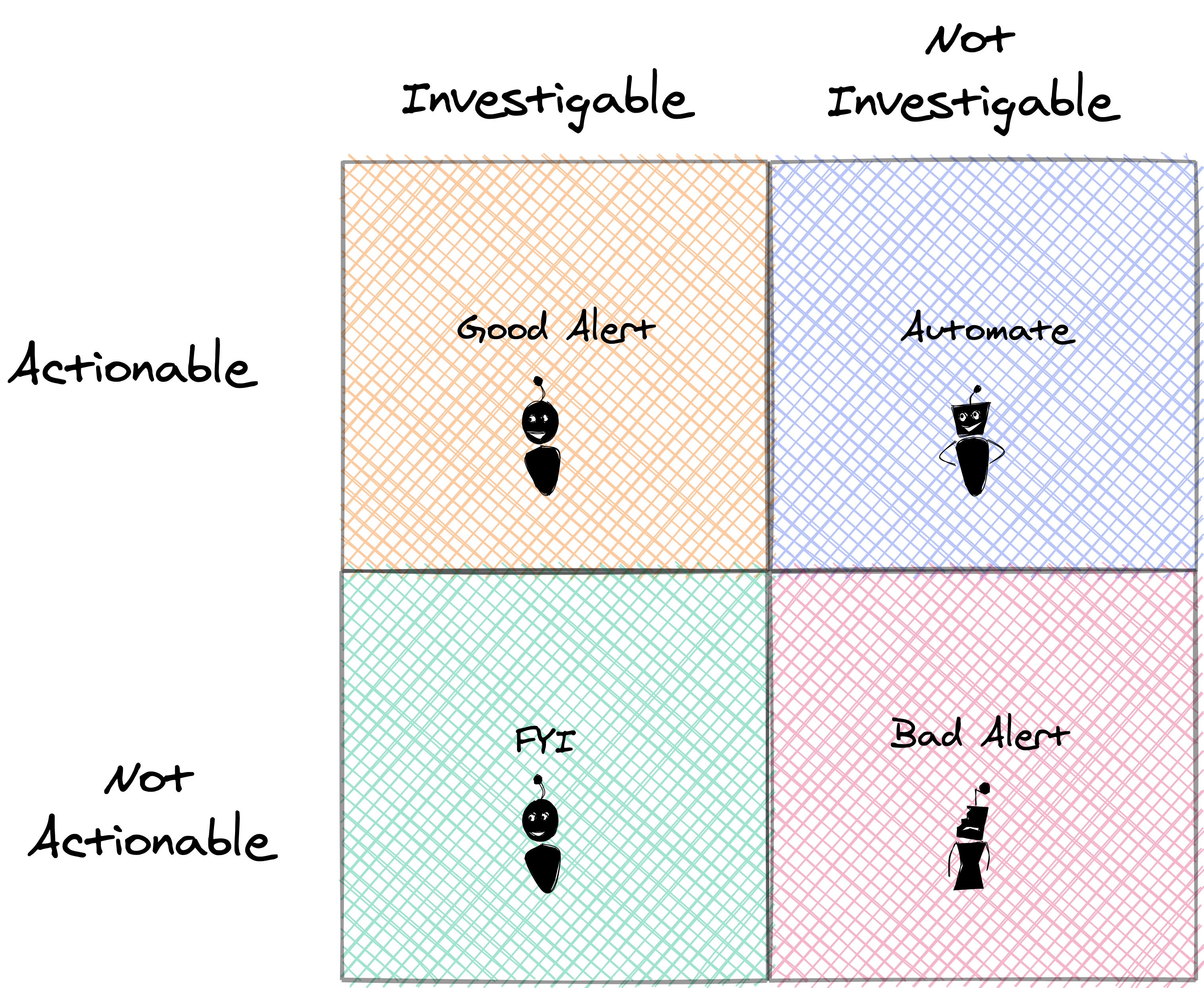
I found this good framework to create a good alert. It needs to have these properties:
Actionable: Indicates a problem for which the recipient is well placed to take immediate action. Investigable: Indicates a problem whose solution is not yet known by the organization.
Do you need to take an action every time? No, you can specify a capacity limit, and then once the metric reaches this limit you can have the first support acting up on it, then when it reaches the second limit then you have a different action like calling the second line support, or calling a script to restart a service, etc.
Sometimes there is no action to take. For example, “CPU utilization” or “Packet loss.” These are some classic FYI alerts. Instead of alerting, these things should appear on a dashboard for use in troubleshooting when a problem is already known to exist.
Do you need to send the alert straight away? Also no, especially when you have mechanisms of self-healing. There’s no need to bother a human to fix the issue; the response should be automated.
Depending on your recovery strategy, you can wait 5, 10, or15 minutes to check if the metric is still showing a problem, and then, if it is you can raise the alert accordingly. In the alert, you can always have a link to the documentation with recovery steps (e.g. a “runbook” indicating steps to perform).
Remember to have an FYI for when the problem is fixed as well, so in case something has failed in the middle of the evening and in the morning is working, you get the latest update about the problem.
Always keep records and logs to investigate what happened and how the system reacted.
Dan Slimmon has a good spreadsheet example of an alert framework:
Monitoring and Alert Tests
Independently the tool you are using for your metrics and alerts: Grafana, Cloudwatch, Sensu, Prometheus, or New Relic. It is important to have a test strategy to cover this critical part of your system.
Some common tests you need to perform are much more Devops related, like scaling down some instances on AWS, simulating a high memory load with scripts, or even creating scripts specific to remove log files from the Docker container.
Points to keep in mind:
Is it worth automating?
Think about if you have a lot of changes and maintenance to the project. How much effort would be to create the automation for these scenarios? How complex these scenarios would be? Does automating them bring any real value?
There are some tools that you can use to perform chaos engineering:
AWS FIS (Fault injection Actions Simulator) to automate some of the scenarios and add to your continuous delivery pipeline. It’s a fully managed service for running fault injection experiments on AWS that makes it easier to improve an application’s performance, observability, and resiliency.
Chaos Mesh utilizes chaos experiments within Kubernetes environments. It’s able to use various types of scenarios related to fault simulations within a distributed system.
Many other tools can be used and you can check the list in this post.
At what stages do you want to test and what scope?
Check if you need to do manual smoke tests for each feature and then have a bigger regression after merging the tickets, or manual test for the feature and at the same time add the automation for this scenario, so at the end of the pipeline, you have the full regression.
Maybe you don’t even need to have automation running for this project and just doing manual feature tests for the tickets and having a report with the full regression scenarios is enough
Whatever is the strategy that you choose, make sure you have the max confidence you can have with the current constraints and a plan to improve in the near future.
Automating these tests is complex and always involves a good knowledge of infrastructure. I personally had and still have to do a lot of research when it comes to it.
Hello all, I have been wondering what will be the trends for this year. Last year, I noticed an increase in accessibility and performance tests concerns because of the increased number of users going online due to the pandemic.
I believe this is going to continue this year and then we will definitely have an increase on the other trends that were already around for the past years. I have condensed some of these trends here:
Blockchain
Think about how the world changed after the internet, everybody is connected. Billions and billions of transactions are made per second, because of that, the concern with the security is even more important. Blockchain arrived with the idea of making it difficult or impossible to change, hack, or cheat the system. Blockchain is essentially a digital ledger of transactions and smart contract (chaincode) services to applications that is distributed across an entire network of computer systems.
This has been a hot topic in the past years, so nothing really new, but you will definitely see an increase as people are still learning and understanding what are the benefits of it and what are the problems that Blockchain solves. Once you understand you never go back.
Augmented Reality
Again nothing really new here, you can see videogames have been using this a lot and it was definitely a boom when you could catch Pokemons in the middle of the street !
With Augmented reality (AR) you can have a real-world interactive experience. The objects from the real world are enhanced by the computer-generated perceptual information, or even combined with digital created objects. You can see an increase on this trend as again people are getting more and more online and avoiding going to the stores because of the pandemic. Now you have the ability to try clothes online for example.
I have never really joined a project with Augmented Reality, but this would be another challenge since you need to keep in mind things like speed you move, lights, objects and other variants.
Chatbots and Artificial Intelligence
I know many people hate chatbots but, for someone that hates calls or just wants to make a quick question, or even just want things to be solved as fast as possible like me, this is the right option. Of course there is still a lot to improve on the machine learning side of the technology, but depending on the how you were able to train the bot, you can even think you are talking to a real person.
I am not going to deny that there is a lot of training of words and phrases until it feels like talking to a human but, some chatbots are really useful, for example if you need to return a purchase on Wish app. Today, chatbots are used most commonly in the customer service space, assuming roles traditionally performed by living, breathing human beings such as Tier-1 support operatives and customer satisfaction reps.
Artificial Intelligence (AI) is here to stay since the beginning of its creation. Big companies like Tesla, Amazon (Alexa), Apple (Siri) are more and more sophisticated. You can expect Machine Learning to be used in the automated tests more and more and also to think about the tests you will need to perform on AI projects.
Mobile Apps (Fitness, Mental Health, E-commerce, Services in general)
It is rare to find a person that doesn’t have a smartphone nowadays, even kids need to have so the parents can contact them to see if everything is okay. The pandemic brought more people to look for mental health and fitness apps than ever, is this going to stay even after our current situation ?
Mobile tests are way more full of details, things you need to consider, like the speed of the internet connection, orientation of the screen, sending the app to the background and opening again… The market is flooded with millions of apps and we have too many options now, so how will new apps find their place? Quality of the service, Usability and Price.
Usability and Accessibility Testing
This is another hot topic as the pandemic pushed more people to go for online services. Keeping accessibility tests in mind you will help people with disabilities to be able to navigate and interact with websites and tools. It also means that they can contribute equally without barriers.
Usability Tests is more about the design of the products. People don’t want to tap 300 times to be able to login or pay for a product, your app needs to be efficient, effective and satisfying. A lot of people don’t realise how this is important, but once you lose a client because of a small mistake it might be hard to get it back.
Internet Of Things (IoT)
Share data and automate services are a must have ! Nowadays you need to have the option to share your fitbit steps with your scale, for example. There is a huge demand to access, create, use and share data from any device.
The thrust is to provide greater insight and control, over various interconnected IOT devices. Which means you need to have the option to tell Alexa to turn on or off the lights when you are too tired to get out of the bed to do it.
I particularly didn’t see too much movement in this area last year, maybe because of all the other more urgent things we had to deal with, but this is another thing that is going to continue increasing, even though I can see a lot of security concerns around having everything connected. Imagine if somebody is able to hack your printer and then getting access to your front door lock ?
Data Protection and Security Tests
This is something you need to keep in mind every time you have a new feature coming up, or even updating a current feature. We need to identify the threats in the system and measure its potential vulnerabilities, so the threats can be encountered and the system does not stop functioning or can not be exploited.
Security tests were always important, but I always felt it was a bit neglected until something bad happens, then was treated as first priority. Here in Europe we need to be super careful with the GDPR rules and make sure we are not exposing personal data anywhere. So, another thing to keep in mind as if we have more people accessing the internet, it means we have more people trying to steal data as well.
Coding Skills and QAOps
Another name for the QA role, like we don’t have enough 😂 (QA, Tester, SDET, Software Developer in Test, Test Automation Engineer, Full Stack QA and the list goes on…). What is this new QAOps name ?
It is a combination of Quality Assurance (QA) and software operations. QAOps combines QA practices with software development and IT operations to develop a long-term, integrated operational delivery model.