Code smell is everything that can slow down your process or increase the risk of implementing bugs when doing maintenance.
The vast majority of the places that I have worked think it is okay to have an automation project with poor quality. Unfortunately, this is an idea shared by many QAs as well. Who should test the test automation ? It is probably alright to have duplicated code, layers and layers of abstraction… After all, it is not the product code, why should we bother, right ?
 Automation is a development project that should follow the same best practices to avoid code smells. You need to ensure the minimum of the quality on your project, so: add a code review process, a code quality tool, and also test your code before pushing the PR (like changing the expectations and see if it is going to fail).
Automation is a development project that should follow the same best practices to avoid code smells. You need to ensure the minimum of the quality on your project, so: add a code review process, a code quality tool, and also test your code before pushing the PR (like changing the expectations and see if it is going to fail).
Of course you don’t need to go too deep and create unit/integration/performance tests for your automation project (who test the tests right ?), but you definitely need to ensure you will have a readable, maintainable, scalable automation project. This is going to be maintained by the team, it needs to be simple, direct and easy to understand. If you spend the same amount of time on your automation and on your development code, something is wrong.
You want to have an extremely simple and easy to read automation framework, so you can have a lot more confidence that your tests are correct.
I will post here some of the most common anti-patterns that I have found during my career. You might have come across some others as well.
Common code smells in Automation framework
– Long class(God object), you need to scroll for hours to find something, it has loads of methods and functions. You don’t even know what this class is about anymore.

– Long BDD scenarios, try to be as simple and straight forward as possible, if you create a long scenario it is going to be hard to maintain, to read and to understand.

– BDD scenarios with UI actions, your tests should not rely on the UI, no actions like click, typed, etc. Try to use more generic actions like send, create, things that even if the UI changes the action doesn’t need to change.

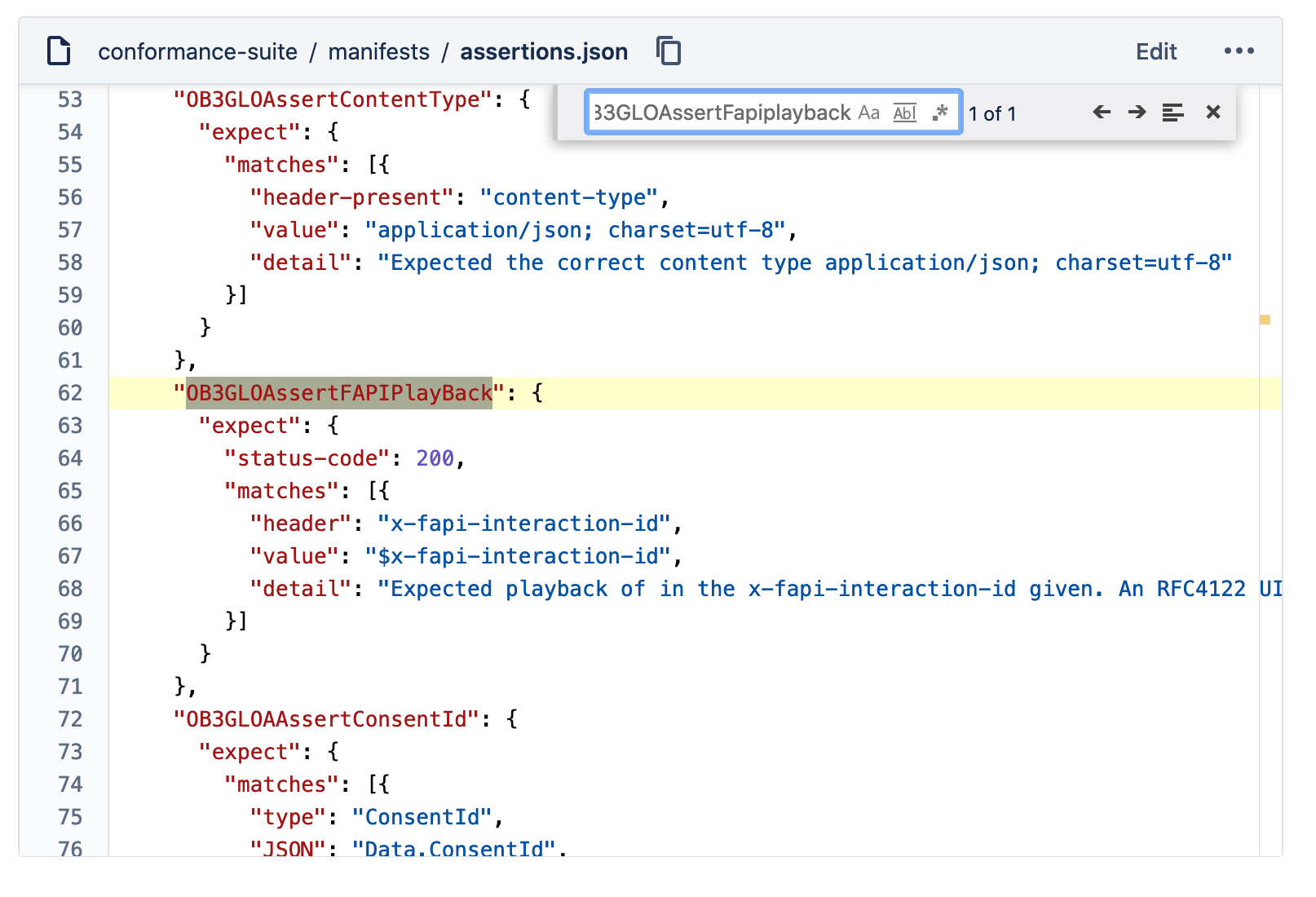
– Fragile locators / Xpath from hell, any small change on the UI would fail the tests and require to update the locator.
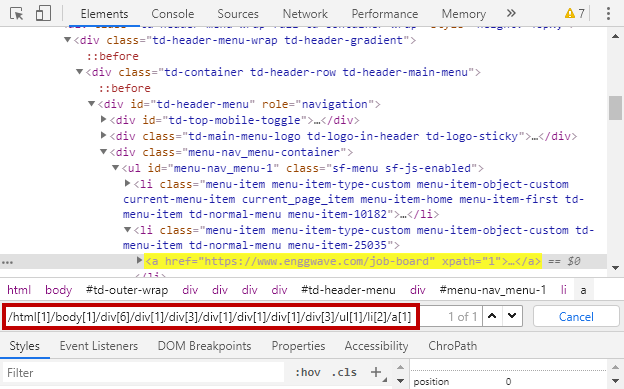
– Duplicate code, identical or very similar code exists in more than one location. Even variables should be pain free maintenance. Any change means changing the code in multiple spots.

– Overcomplexity, forced usage of overcomplicated design patterns where simpler design would be enough. Do you really need to use dependency injection ?

– Indecent Exposure, too many classes can see you, limit your scope.
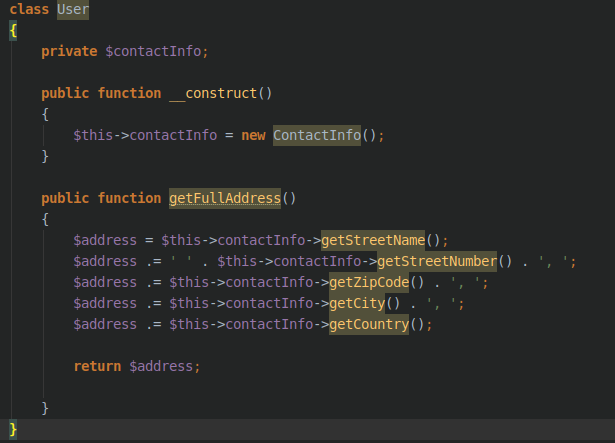
– Shotgun surgery, a single change needs to be applied to multiple classes at the same time.
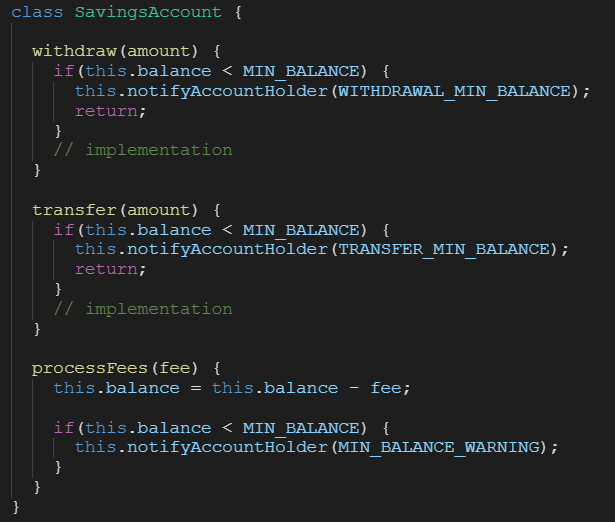
– Inefficient waits, it slows down the automation test pipeline, can make your tests flaky.

– Variable mutations, very hard to refactor code since the actual value is unpredictable and hard to reason about.

– Boolean blindness, easy to assert on the opposite value and still type checks.

– Inappropriate intimacy, too many dependencies on implementation details of another class.

– Lazy class / freeloader, a class that doesn’t do much.

– Cyclomatic complexity, too many branches or loops, this may indicate a function needs to be broken into smaller functions, or that it has potential for simplification.

– Orphan variable or constant class, a class that typically has a collection of constants which belong elsewhere where those constants should be owned by one of the other member classes.
– Data clump, occurs when a group of variables are passed around together in various parts of the program, a long list of parameters and it is hard to read. In general, this suggests that it would be more appropriate to formally group the different variables together into a single object, and pass around only this object instead.

– Excessively long identifiers, in particular, the use of naming conventions to provide disambiguation that should be implicit in the software architecture.

– Excessively short identifiers, the name of a variable should reflect its function unless the function is obvious.

– Excessive return of data, a function or method that returns more than what each of its callers needs.

– Excessively long line of code (or God Line), a line of code which is too long, making the code difficult to read, understand, debug, refactor, or even identify possibilities of software reuse.

How can you fix these issues ?
- Follow SOLID principles ! Class, methods should have a single responsibility !
- Add a code review process and ask the team to review (developers and other QAs).
- Lookout how many parameters you are sending. Maybe you should just send an Object.
- Add locators that are resistant to UI changes, focus on ids first.
- Return an object with the group of the data you need instead of returning loads of variables.
- Focus to name the methods and classes as direct as possible, remember SOLID principles.
- If you have a method that just type a text in a textfield, it maybe grouped together to a function that is going to perform the login().
- If you have long lines of code, you might want to split it up into functions and move some of them to a variable and then formatting this variable, for example.
- Think twice about the boolean assertions, add a comment if you think it is not straight forward.
- Follow POM structure with helpers and common shared steps/functions to avoid long classes.
- Do you really need this wait ? You might be able to use a retry or maybe your current framework have ways to deal with waits properly.
- Add a code quality tool to review your automation code (eg. ESlint, Code Inspector)
Resources:
https://en.wikipedia.org/wiki/Code_smell
https://pureadmin.qub.ac.uk/ws/portalfiles/portal/178889150/MLR_Smells_in_test_code_Dec_9.pdf
https://www.sealights.io/code-quality/the-problem-of-code-smell-and-secrets-to-effective-refactoring/
https://slides.com/angiejones/automation-code-smells-45
https://medium.com/ingeniouslysimple/should-you-refactor-test-code-b9508682816