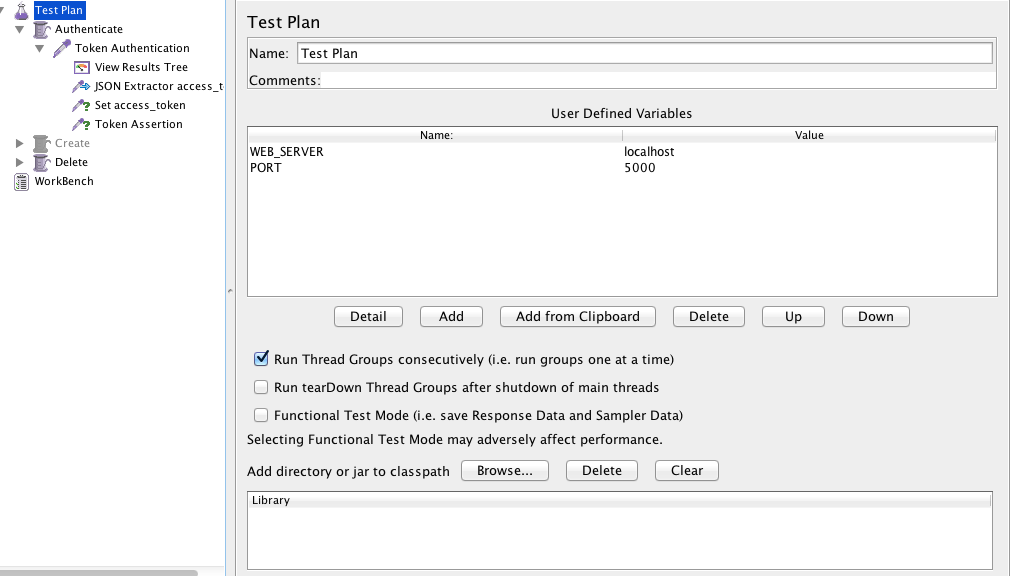
Here I am again talking about BDD haha 😀
I am trying to implement the best practices of BDD in my company, it’s quite hard because most of them are developers and they have their own way to think which is different for Business and QA professionals. Other day I was discussing with a guy who had read a post about BDD and suddenly he entitled himself as an expert ! Really, this is the most common attitude you will find in IT atmosphere.

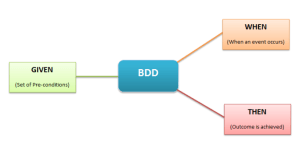
So, the structure is exactly like this and some people like to write the Given step in the past, but this is the thing, you don’t really need to write the first step in the past, some cases you can write in the present tense.
Like:
Given I have xxx…
When I do xxx…
Then I should see xxxx…
The first step is a situation you have now like I am logged on the system, you don’t need write always in the past, this is not a rule. You need to write something is evident, this is the aim. So, if you want write in the past the Given, you will have something like:
Given I have logged xxx…
When I do xxx…
Then I should see xxx…
Except the Given that you can choose what is the best option for your scenarios, the When and Then you need to follow the right tenses, When in present Tense and Then in the future tense.
BDD structure:
The features must have .feature as the extension of the file and you need put the features in the correct path, if you don’t do that Cucumber won’t work. If you want to run with Jbehave you don’t need follow the right structure, you can change this on the pom file if you are using Maven.
Where should feature files be kept
Some people don’t like to keep them on git with the project, they would like to see the scenarios on JIRA, but you will need to update and maintain in both of the places, for this reason I always put on github.
How should we write feature files
There are generally two ways of writing feature files – Imperative and Declarative
Imperative style of writing a feature file, is very verbose, contains low level details and too much information.
Pros: person reading the feature file can follow the step-by-step
Cons: Because of too much detail, the reader can lose the point of the story and the tests. The feature file becomes too big, difficult to maintain and likely to fail due to UI updates.
Declarative style of writing a feature file is concise and to the point, contains only relevant information about the story.
Pros: The declarative style is more readable as it contains less steps in the scenario. The reader can easily understand the scope of the test and quickly identify if any key elements are missing.
Independence of Scenarios
Scenarios should be independent of one another. This means that each and every scenario is stand-alone and should not refer to or depend on functionalities/conditions in other scenarios.
Redundancy and Refactoring
- Avoid repetitions! Repetitions or identical steps indicate the need forrefactoring. Refactoring denotes that a scenario should be split into multiple ones while the original meaning is preserved.
- How many
Givens, Whens and Thens (including Ands andButs) should you use? As a rule of thumb, there should be amaximum of 3 to 4 consecutive Givens and Thens. Otherwise this indicates a need for refactoring. Whens should be used very sparingly! Usually only include one When.
- Generally, favour many simple scenarios over few complex ones.
Resources:
http://www.testingexcellence.com/bdd-guidelines-best-practices/
https://blog.grandcentrix.net/gherkin-guidelines-and-best-practices/